Tutorial (20 minutes)
Overview:
CancerGD.org provides a search interface for genetic dependencies identified in loss-of-function screens in panels of tumor cell lines. A genetic dependency is identified when there is a statistical association between the presence of a particular mutation and increased sensitivity to the inhibition of a specific gene. These dependencies are identified by integrating large-scale loss-offunction screens in panels of cell lines with genotype data for the same cell lines. In CancerGD we store all nominally significant dependencies (P < 0.05) with a common language effect size > 65%. A goal of this resource is to help understand genetic dependencies in the context of known functional interaction networks (e.g. protein-protein interactions). Towards this end we have developed simple functionality to identify those genetic dependencies that occur within pathways (i.e. where the driver gene and the target dependency belong to the same pathway) and between pathways (i.e. where the dependencies associated with a given driver gene belong to the same complex or pathway as each other). This is inspired by work in yeast that used the same categories to interpret genetic interactions. To further facilitate follow on studies we have also annotated all dependencies in the database according to the availability of inhibitors for the target genes.
Here we provide a simple tutorial that takes the user through the main functionality of www.cancergd.org. We show how CancerGD can be used to browse and analyse the dependencies associated with ERBB2 amplification in the Campbell et al. paper published in Cell Reports (2016). This tutorial should take approximately 20 minutes to complete.
Step 1 – Retrieving the dependencies associated with a driver gene
On the main search page, in the search Driver gene field type 'ERBB2', in the Tissue type dropdown select 'Pan cancer', and in the Study dropdown please select 'Campbell(2016)'. Click the Search button.

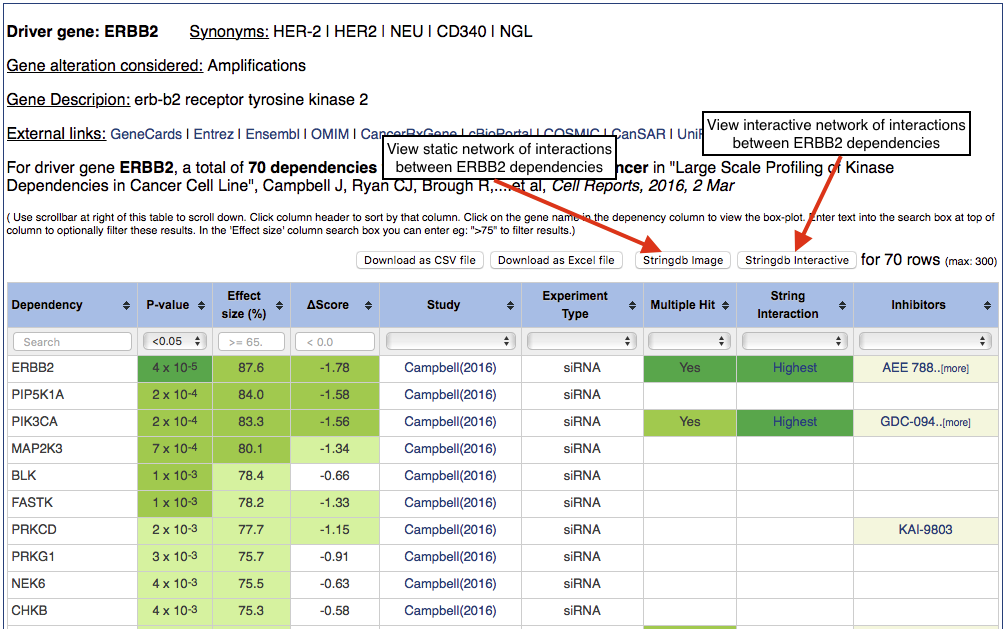
You will be presented with a table of results resembling the below image. The top of the page provides details (gene synonyms, a gene description, links to the gene on external resources) for the selected driver gene (ERBB2). The bottom of the page is a table displaying all of the nominally significant (p < 0.05) dependencies associated with the selected driver gene (ERBB2) in the selected tissue (pan-cancer, i.e. across all tissue types) from the selected study (Campbell et al.). You can optionally sort this table by clicking the toggles in the header row. For most columns it is also possible to filter using the plain text forms or drop-down menus at the top of the table. You can also optionally download this table as a CSV file (which you can open with Excel or similar application) by clicking the 'Download as CSV file' button above the table.
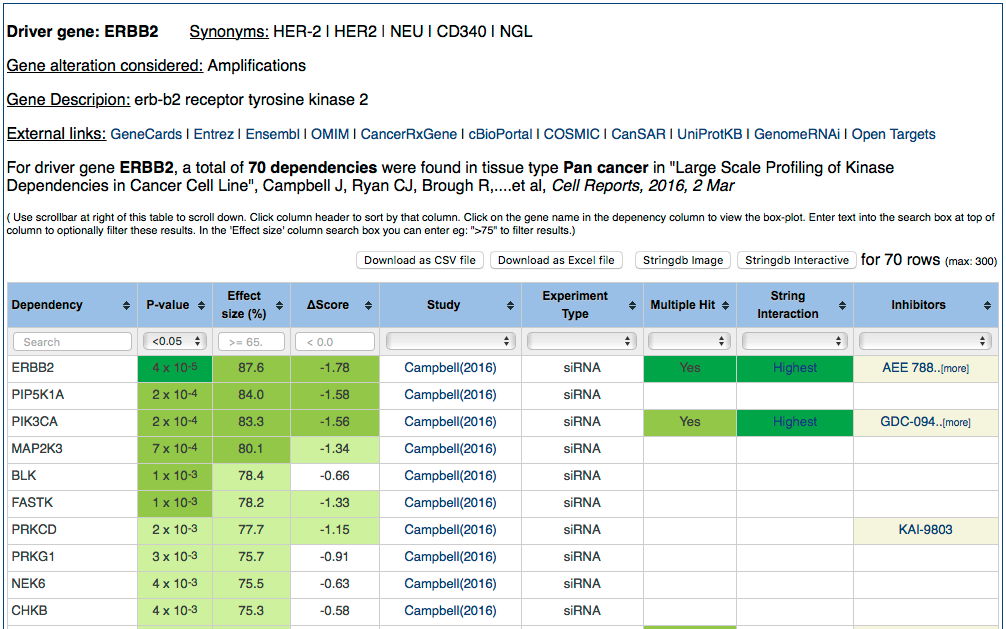
Clicking on any gene name in the 'Dependency' column will present the user with a view of the evidence supporting that dependency. Click on MAP2K3 (left column, fourth row in the table) to proceed to the next step.
Step 2 – Viewing the data supporting individual dependencies
You will be presented with a window resembling the below image. This view presents the data supporting the association between ERBB2 amplification and sensitivity to RNAi reagents targeting MAP2K3.
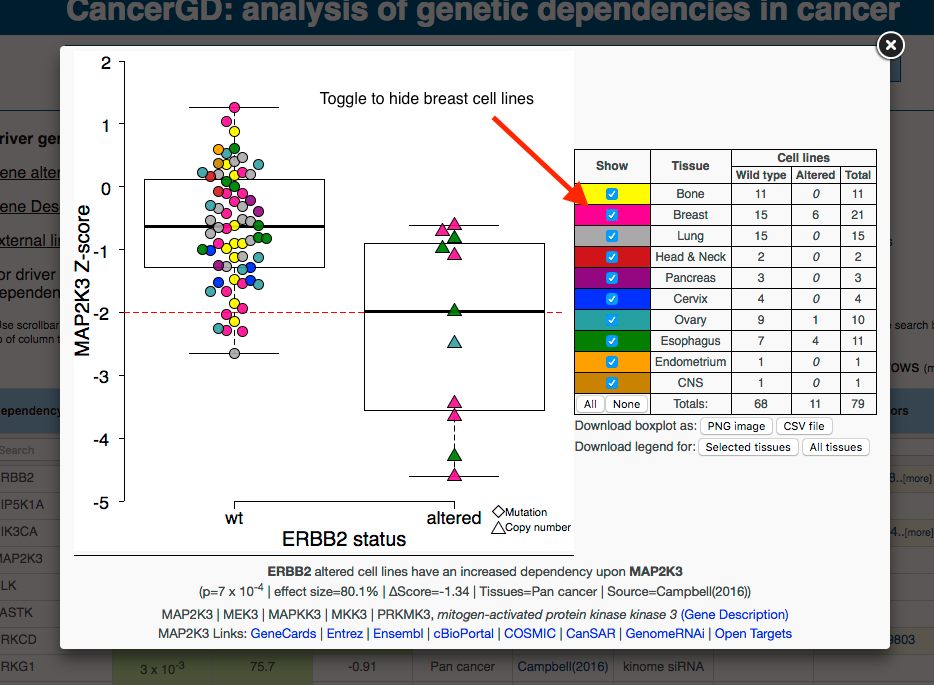
This is an interactive box plot that displays the sensitivity of cell lines partitioned according to ERBB2 status to RNAi reagents targeting MAP2K3. The cell lines featuring an alteration of ERBB2 are displayed on the right and the cell lines without the alteration are on the left. Each colored shape (circle, diamond or triangle) represents a cell line and the position along the y-axis indicates how sensitive that cell line is to the RNAi reagents targeting the gene indicated (MAP2K3). A lower position on the y-axis indicates greater sensitivity. The colors indicate the tissue of origin for each cell line, as indicated in the legend on the right hand side. Toggle check-boxes in the legend facilitate hiding or displaying cell lines from specific histologies. To see how the dependency between ERBB2 and MAP2K3 appears when breast cell lines are removed uncheck the box beside 'Breast' in the legend.
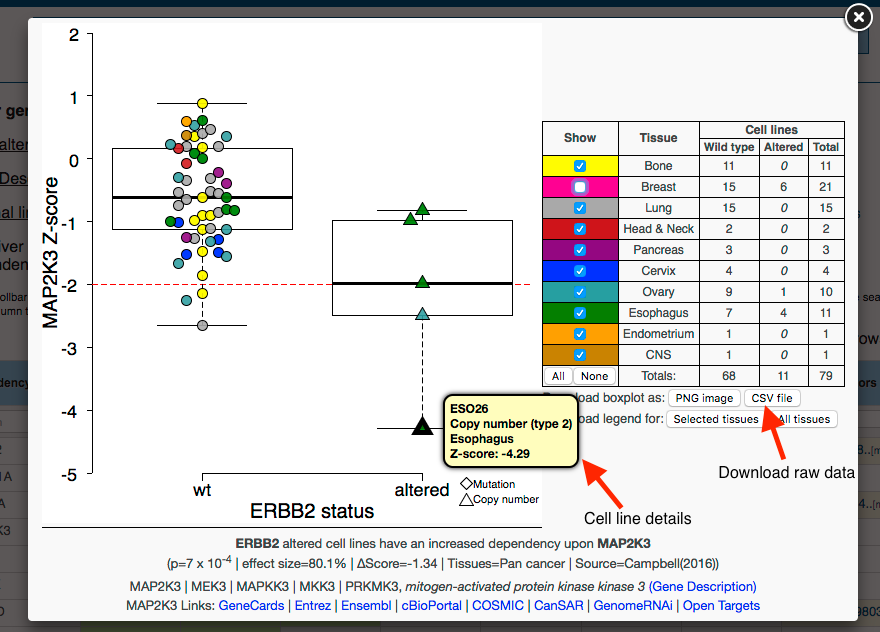
To download a high-resolution copy of this image click 'Download boxplot as: PNG image'. To download the raw data supporting this dependency in a comma separated text file, click 'Download boxplot as: CSV file'. This can be opened with Microsoft Excel or similar applications.
To see the details associated with a specific cell line hover your cursor over the shape corresponding to that cell line (e.g. above we hover over the cell line with the greatest sensitivity to MAP2K3 inhibition).
Click the X in the top right to close this image and return to the table that lists genetic dependencies.
Step 3 – Filtering dependencies with a known functional relationship to the driver gene
One of the goals of this resource is to facilitate the interpretation of genetic dependencies and to develop filters to prioritize promising candidates for follow up studies. The simplest approach is to focus on dependencies that have a known relationship (e.g. a protein-protein interaction) with the driver gene. To identify these - choose 'Any' in the 'String Interaction' column. This will filter the table to show only the genetic dependencies that have a functional relationship (e.g. protein-protein interaction) with ERBB2 as displayed below.
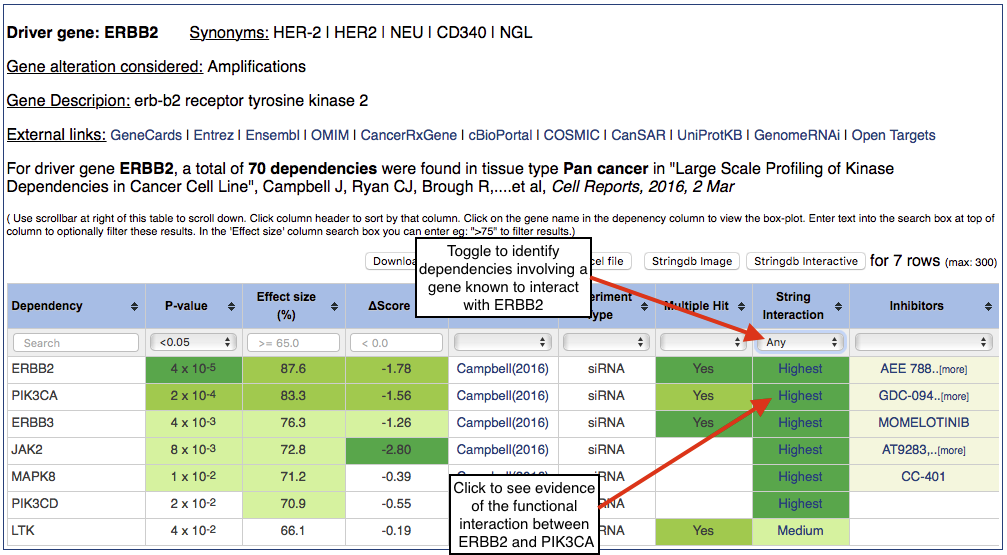
This identifies the ERBB2 downstream effector PIK3CA and the ERBB2 binding partner ERBB3 among others. These functional relationships are obtained from the STRING database. Clicking on text inside the String Interaction column (e.g. Highest) will bring the user to the STRING database where the data supporting the functional interaction between the driver gene and the dependency will be displayed.
Step 4 – Identifying interactions between the dependencies associated with a driver gene
An alternative to identifying the known functional interactions between a driver gene and its dependencies is to try to understand the relationship between all of the dependencies associated with a given driver gene. In this way it may be possible to identify pathways or protein complexes that the driver gene is associated with an increased dependency upon. For this analysis we again rely on the STRING database. To view all of the interactions between the dependencies associated with ERBB2 click on the 'Stringdb Image' button above the dependencies table.
This will take a moment to retrieve an image similar to that below showing high-confidence functional interactions between the genes identified as ERBB2 dependencies. You can see that ERBB2 amplification is associated with an increased dependency upon a group of kinases functionally related to ERBB2 and PI3K signaling, as well as a group of genes involved in map kinase signaling.
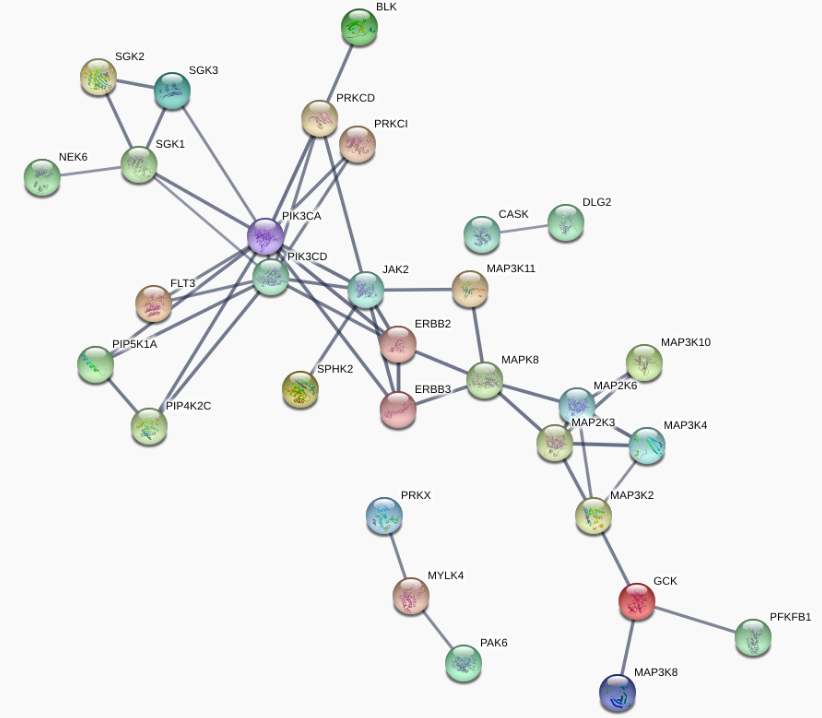
Click the X in the top right of the Stringdb image to close the image and return to the table listing dependencies. By selecting 'Stringdb Interactive' instead of 'Stringdb image' you can view an interactive version of this network on the STRING website. This will allow you to view the evidence supporting each functional interactions, to alter the layout of the network, and to filter the network in different ways.
Step 5 – Identifying dependencies that can be exploited with existing inhibitors
A further goal of CancerGD is to facilitate follow on experimentation. One means to further explore or validate a dependency is to see if the same effect is observed using small molecule inhibitors rather than RNAi reagents. To that end we annotate all of our dependencies according to the availability of inhibitors. To view genes with available inhibitors, select 'Any' in the 'Inhibitors' column toggle. You will see a view resembling the below.
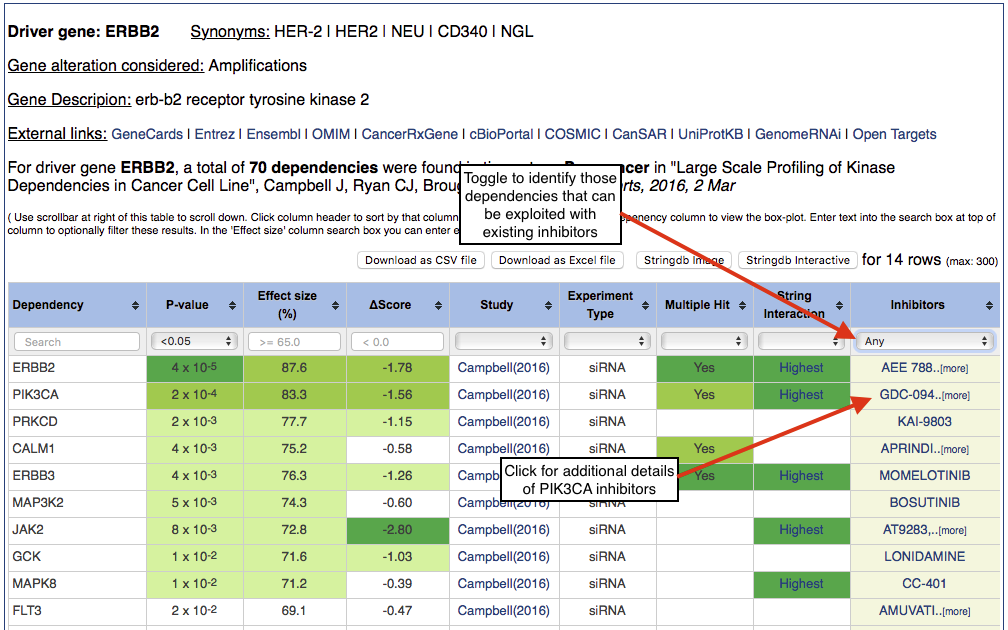
This filters the dependencies so that only those genes with known inhibitors are presented. The mapping from genes to inhibitors is taken from the DGIdb resource. Clicking on any inhibitor name in the Inhibitors column will bring the user to DGIdb, where details on the inhibitor are provided. For some genes there are more inhibitors available than can be presented in the Inhibitors column. These are indicated with the text [more]. Clicking on [more] in any entry in the Inhibitors column will display the full list of inhibitors associated with that gene in a window like that shown below:
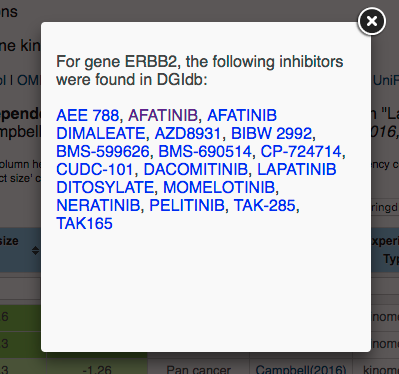
Clicking any inhibitor name within this window will bring the user to DGIdb, where details on the inhibitor are provided. Click the X to close this window.
Step 6 – Identifying dependencies that have been observed in multiple datasets
A dependency observed in any one screen may be a statistical artefact, a context specific dependency, or a false positive resulting from the off-target effects of gene targetting reagents. Those dependencies observed in multiple independent datasets may make more promising candidates as they are less likely to be artefacts or false positive effects. To prioritise these for further validation, CancerGD allows easy filtering of the dependencies observed independently in multiple datasets. To view dependencies that have been associated with the same driver gene in the same tissue type, select 'Yes' in the 'Multiple Hit' column toggle. You will see a view resembling the below.
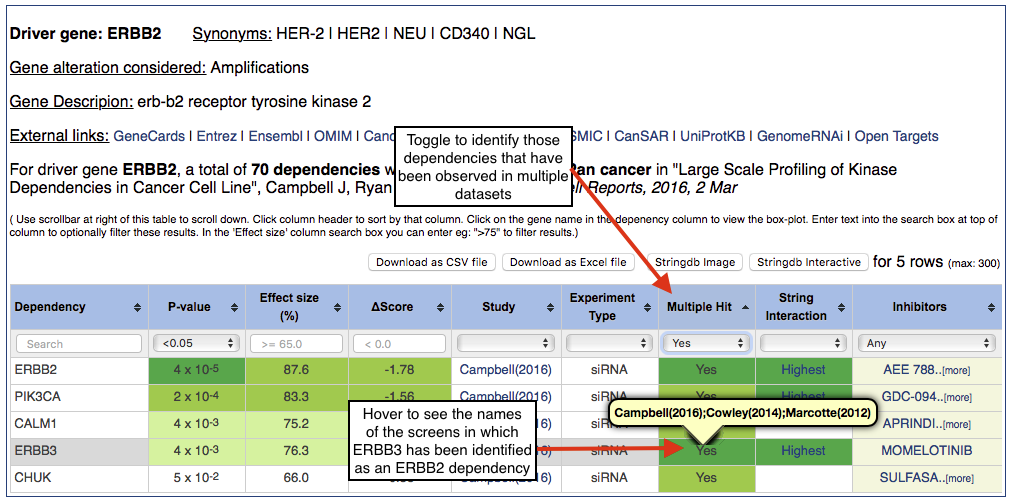
Hover over the 'Yes' text in the 'Multiple Hit' column to see the details of the screens that a specific gene has been identified as a dependency in.
Conclusion
You have now completed a tour of the main www.cancergd.org functionality. Further information is available on the FAQ page. We welcome feedback through the contact page.